

There is a lot of discussion about the appropriate use of AI in the user and market research fields. While AI is a broader field, a lot of the interest and curiosity is around large-language models (LLMs) - thanks to ChatGPT.
The discussions range from people trusting and embracing AI to people being very cautious. A lot of this caution comes from a really good place of protecting our craft and the value we create.
I believe both are very valid and they are talking about different things. In this article, I capture my experience and what I see LLMs do well v/s not.
An overview of LLMs
For LLMs, everything is a mathematical representation. A word (infact, they split words into “tokens”) is represented by numbers (A concept called “embeddings”). The mathematical representation then allows LLMs to compare and find similarities.
To understand how they work, let’s start with a mathematical problem. Let’s take 3 lines plotted on a 2-dimensional graph:
Chart 1: Points A and B are closer to each other than the point C
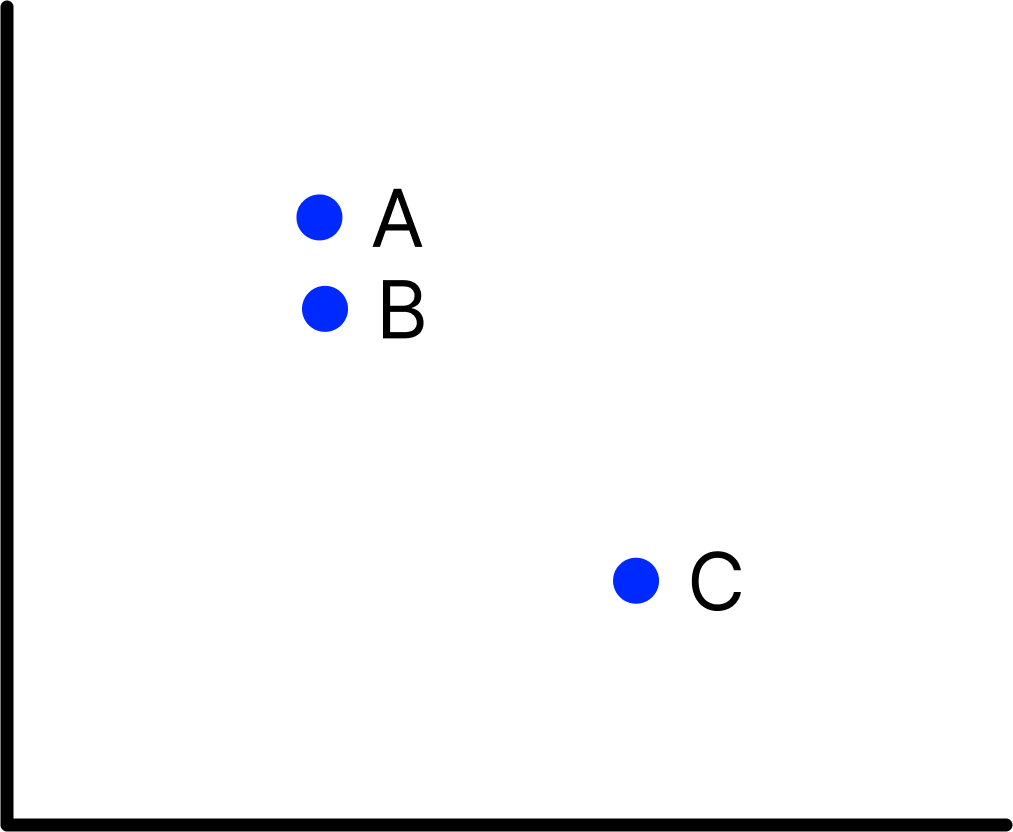
Chart 2: Let’s think of these points as different fruits. Apple and Orange are more similar to each other than Banana
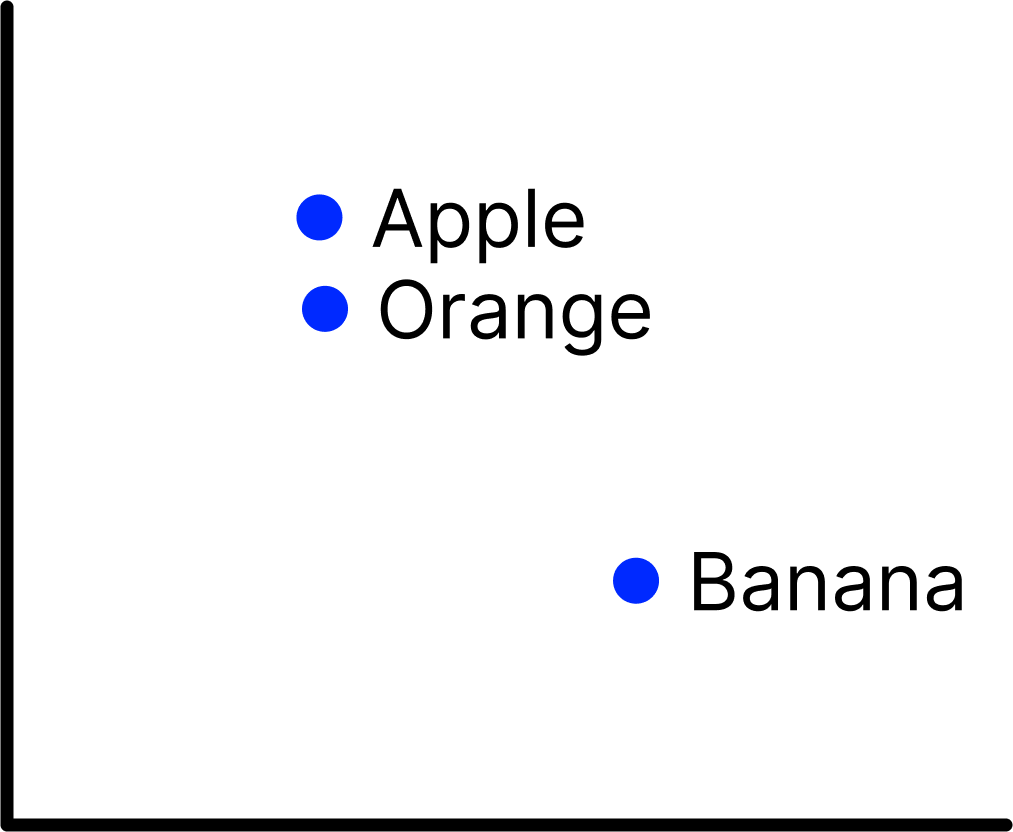
Chart 3: This is based on the dimensions of color and shape
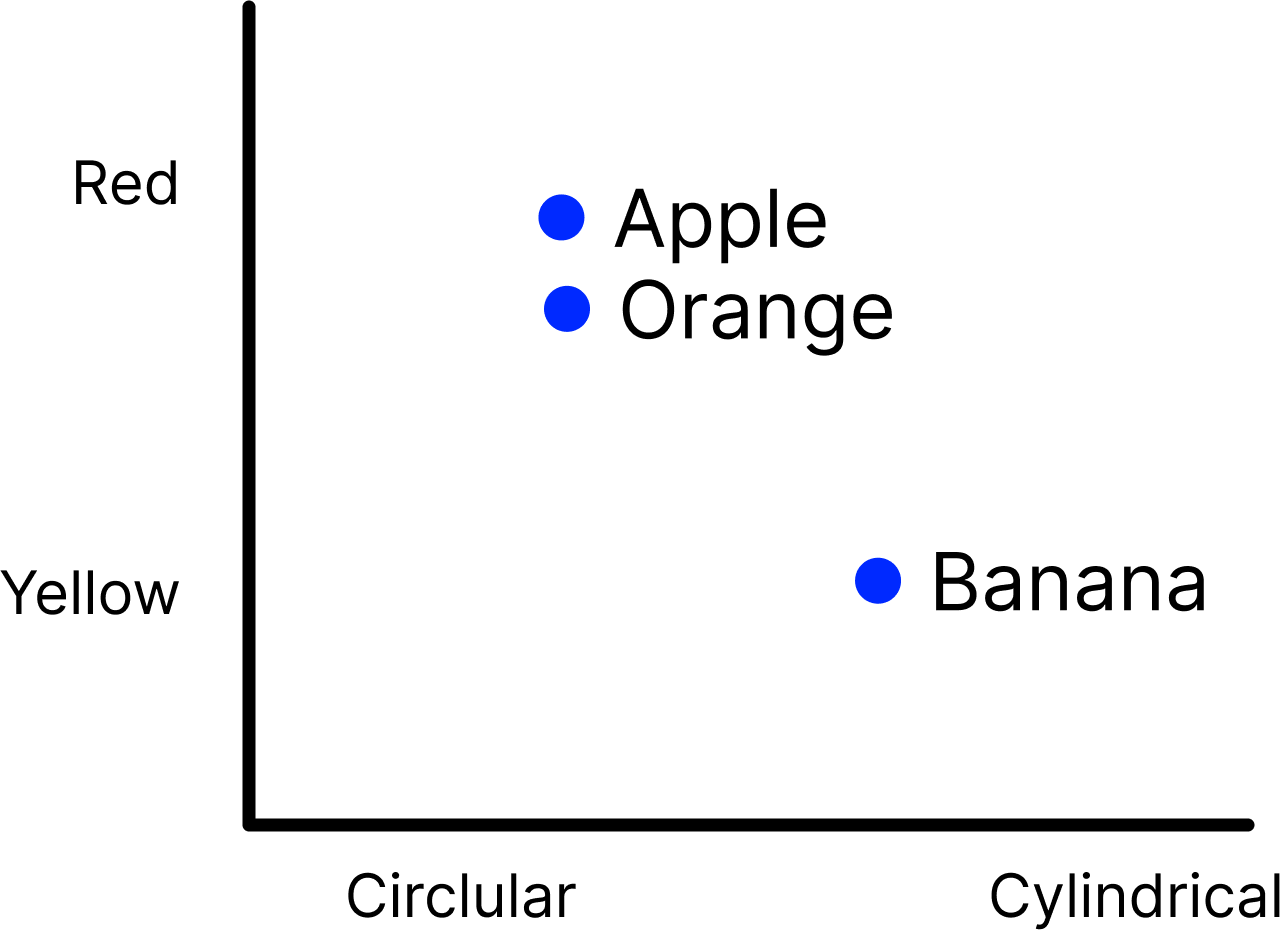
You can imagine adding more dimensions like is season the fruit grows in, is it citrus, how often is it used in salad.. anything that we care about. Based on the specific dimensions these points will move and so will the assessment of similarity.
This is LLM in reverse. LLM would look at a word across 100s of dimensions and assign a score for each dimension. As I mentioned, this is called embedding. Here is an abbreviated example:
"-0.0049455464","-0.0036188485","0.047773916", "-0.027927792", "-0.014974104", "0.017199121", "-0.0023656783","-0.026239848", "-0.031533852", "-0.004820869", "0.0041782996", "0.0038042665", "0.016367937","-0.0020491888", "-0.0073336028", "-0.0031249332", "0.05667398", "-0.014513756", "0.028362565", "-0.029948208", "-0.010031755", "0.009763218", "-0.008356599", "0.0034462179", "-0.03506319", "-0.0026214274", "0.009609769", "-0.028030092", "-0.0010197992", "-0.03680228", "0.0051117833", "-0.0014170094", "-0.009047121", "-0.01288975", "-0.009149421", "-0.005636069", "-0.01299205", "-0.013682572", "0.020395983", "-0.011169838", "-0.0038522193", "0.004699388", "-0.003350312", "-0.010632765", "-0.004862428", "-0.0030338226", "0.0142452195", "-0.008944822", "-0.0065279934", "0.01434752", "0.028720614", "-0.012953687", "-0.0013282964", "0.017122395", "-0.010843758", "-0.020216959", "0.0049903025", "0.024641417", "-0.017621107", "-0.03866925", "0.0052204765", "-0.0317896", "0.0016511795", "0.004635451", "-0.014577693", "-0.004581104", "0.0054602413", "0.021431766", "0.011336075", "0.024411242", "0.010166023", "0.005444257", "-0.008810554", "0.012307921", "0.019270688", "-0.016508598", "-0.006911617" ...These dimensions are not as we humans understand them. It’s based on training data - which is lots and lots of text based on which it starts to extract patterns.
LLMs understand language patterns
With the above, you can start to see that based on the dimensions LLM can say Apples and Orange are more similar than Bananas. So if you were to ask the question of finding round-shaped fruits, it’ll give Apples and Oranges a higher score than bananas and can surface that as the answer.
All this without knowing what each of these fruits really mean. Hidden inside my reference is also the meaning of circular or various colors and that works the same way too.
This is the key to understanding where LLMs can be used in research.
LLMs do two main things
Search
Construct sentences
We already touched on search when I talked about asking LLM to find round-shaped fruits. This is different than traditional keyword-based search. Instead of looking for specific words, the LLM “embeds” the query to get the numerical representation of the question and calculates distances to find the answers. This is where all the magic of LLMs and complexity it.
Based on the similar words, it puts together a sentence, one word at a time. For example, the response might start with “American” and then the next word would be “Car”, “Dream”, “Flag” etc.. the LLM will select the next word based on the context of the query. Let’s say the next word is “Dream”, so now it has “American Dream” which becomes a part of the context and it looks for the next word, and so on.
So what does this mean for us?
This means that we can use LLMs for searching and then presenting the results back in a meaningful manner. However, we cannot expect it to understand or represent the meaning the way humans do. Not yet at least.
So what is the difference? It is blurry. Does the idea that it understands round-shaped fruits not mean that understands the meaning of the words? If someone were to ask us to explain the meaning of a word, we’d essentially use other words to explain it. Which is the same as clustering the way LLM does. So, one could argue that it does understand the meaning.. to some degree.
It understands what is said and has a limited understanding of what is implied or how is the information intended to be used.
This is where, in my opinion, ideas like synthetic users are not yet ready. They might get there in the future. creating a synthetic user based on a word cluster is just that.. words put together. However, the judgment needed to create a good person goes much beyond embeddings and similarity scores. It’s not a word clustering problem. It is a problem of deeper meaning.
However, ideas of natural language search, summarization, concept extraction, identifications of themes, etc are something that LLMs can add significant value to. Here too, we’ll run into limitations of understanding the intent behind search, or concept extraction. And that’s where prompts become useful. By adjusting prompts we can be a lot more expressive about what we are looking for. It’s not different from Google search. You can tweak your query to get different answers.